Introducing cesium
From the reading of electroencephalograms (EEGs) to earthquake seismograms to light curves of astronomical variable stars, gleaning insight from time series data has been central to a broad range of scientific and medical disciplines. When simple analytical thresholds or models suffice, technicians and experts can be easily removed from the process of inspection and discovery by employing custom algorithms. But when dynamical systems are not easily modeled (e.g., through standard regression techniques), classification and anomaly detection have traditionally been reserved for the domain expert: digitally recorded data are visually scanned to ascertain the nature of the time variability and find important (perhaps life-threatening) outliers. Does this person have an irregular heartbeat? What type of supernova occurred in that galaxy? Even in the presence of sensor noise and intrinsic diversity of the samples, well-trained domain specialists show a remarkable ability to make discerning statements about the complex data.
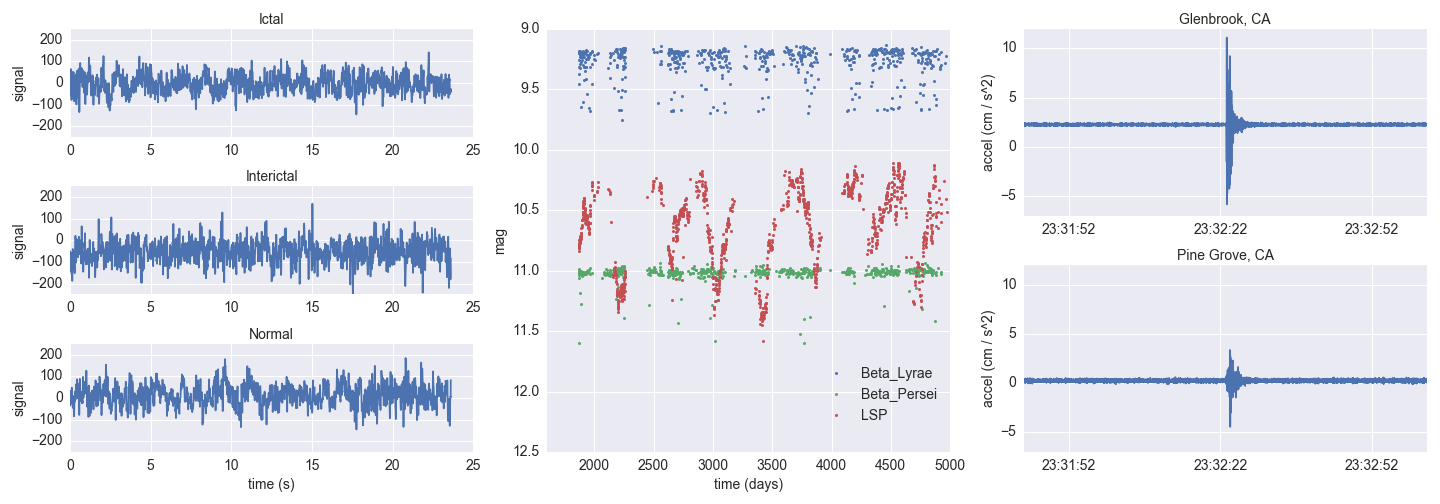
In an era when more time series data are being collected than can be visually inspected by domain experts, however, computational frameworks must necessarily act as human surrogates. Capturing the subtleties that domain experts intuit in time series data (and perhaps even besting the experts) is a non-trivial task. In this respect, machine learning (ML) has already been used to great success in several disciplines, including text classification, image retrieval, segmentation of remote sensing data, internet traffic classification, video analysis, and classification of medical data. Even if the results are similar, some obvious advantages over human involvement are that ML algorithms are tunable, repeatable, and deterministic. A computational framework built with elasticity can scale, whereas experts (and even crowdsourcing) cannot.
Machine learning for domain-science time series inference
Despite the importance of time series in scientific research, there are few resources available that allow domain scientists to easily build robust computational inference workflows for their own data, let alone data gathered more broadly in their field.
Traditional statistical models of time series are often too rigid to explain
complex time domain behavior, while popular machine learning packages deal
almost exclusively with ‘fixed-width’ datasets requiring a uniform number of
pre-computed features. cesium allows researchers to apply modern machine
learning techniques to time series data in a way that is simple, easily
reproducible, and extensible. Being a modern data-driven scientist should not,
we believe, require an army of software engineers, machine learning experts,
statisticians and production operators.
Simplifying the analysis workflow
Building a functioning machine learning pipeline involves much more than
choosing a mathematical model for your data. The goal of cesium is to
simplify the analysis pipeline so that scientists can spend less time solving
technical computing problems and more time answering scientific questions.
cesium comes with a number of out-of-the-box feature engineering workflows,
such as periodogram analysis, that transforms raw time series data to pull
signal from the noise. By also streamlining the process of fitting models and
studying relationships within datasets, cesium allows researchers to iterate
rapidly and quickly answer new questions that arise out of previous lines of
inquiry. We also aim to make analyses using cesium easily shareable and
reproducible, so that an entire process of discovery can be shared with and
reproduced by other researchers. Saved cesium workflows are meant to be
production-ready, meaning that comprehensive machine learning can be applied
not just to data in retrospect but to live, streaming data as well.
Scaling to large datasets
In many fields, the volumes of time series data available can be immense.
cesium makes the process of analyzing time series easily parallelizable and
scaleable; scaling an analysis from a single system to a large cluster should
be easy and accessible to non-technical experts. The analysis workflow of
cesium can be used in two forms: a web front end which allows researchers to
upload their data, perform analyses, and visualize their models all within the
browser; and a Python library which exposes more flexible interfaces to the
same analysis tools. The code for both the web frontend and Python library are
open source and available on Github. In our
next post, we’ll show how the Python library can be used to quickly solve a
classic EEG classification problem.
With thanks to the National Science Foundation and the Gordon and Betty Moore Foundation for support.